Version R3 of the documentation is no longer actively maintained. The site that you are currently viewing is an archived snapshot. For up-to-date documentation, see the latest version.
Nephio user guides
Nephio User Guide
Overview
Nephio is a Kubernetes-based intent-driven automation of network functions and the underlying infrastructure that supports those functions. It allows users to express high-level intent, provides intelligent, declarative automation that can set up the cloud and edge infrastructure, renders initial configurations for the network functions, and then delivers those configurations to the right clusters to get the network up and running.
Technologies like distributed cloud enable on-demand, API-driven access to the edge. Unfortunately, existing brittle, imperative, fire-and-forget orchestration methods struggle to take full advantage of the dynamic capabilities of these new infrastructure platforms. To succeed at this, Nephio uses new approaches that can handle the complexity of provisioning and managing a multi-vendor, multi-site deployment of interconnected network functions across on-demand distributed cloud.
The solution is intended to address the initial provisioning of the network functions and the underlying cloud infrastructure, and also provide Kubernetes-enabled reconciliation to ensure the network stays up through failures, scaling events, and changes to the distributed cloud.
Nephio breaks down the larger problem into two primary areas:
- Kubernetes as a uniform automation control plane in each site to configure all aspects of the distributed cloud and network functions
- An automation framework that leverages Kubernetes declarative, actively-reconciled methodology along with machine-manipulable configuration to tame the complexity of these configurations.
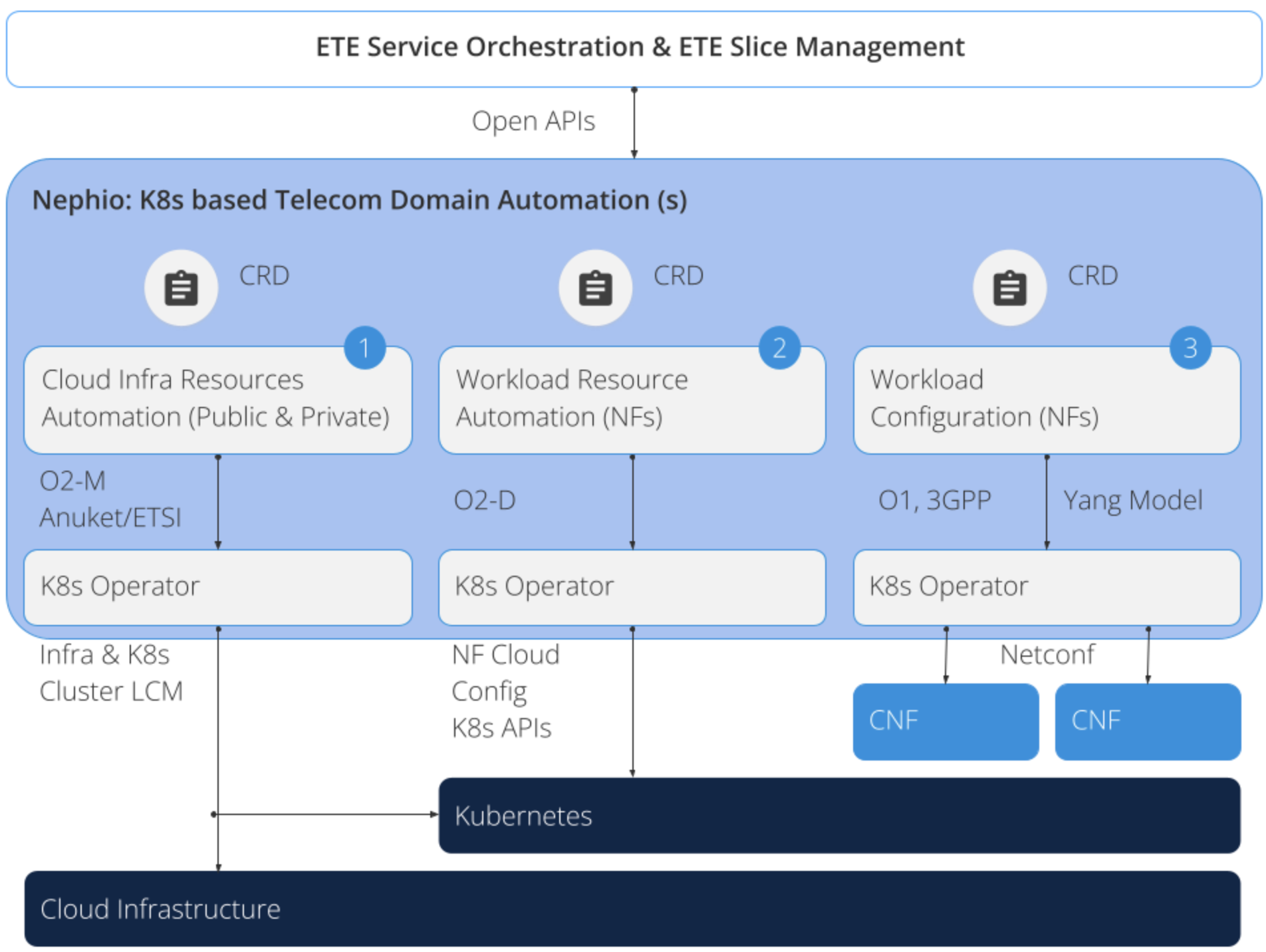
Kubernetes as a Uniform Automation Control Plane
Utilizing Kubernetes as the automation control plane at each layer of the stack simplifies the overall automation and enables declarative management with active reconciliation for the entire stack. We can broadly think of three layers in the stack, as shown below.
- Cloud infrastructure
- Workload (network function) resources
- Workload (network function) configuration Nephio is establishing open, extensible Kubernetes Custom Resource Definition (CRD) models for each layer of the stack, in conformance to the 3GPP & O-RAN standards.
Overview of Underlying Technologies
Custom Resources and Controllers
A Custom Resource Definition (CRD) is an extension mechanism for adding custom data types to Kubernetes. The CRDs are the schemas - analogous to table definitions in a relational database, for example. The instances of those - analogous to rows in a RDBMS - are called Custom Resources or CRs. People often accidentally say “CRDs” when they mean “CRs”, so be sure to ask for clarification if the context doesn’t make it clear which is meant.
In Kubernetes, resources - built-in ones as well as CRs - are processed by controllers. A controller actuates the resource. For example, K8s actuates a Service with Type LoadBalancer by creating a cloud provider load balancer instance. Since Kubernetes is declarative, it doesn’t just actuate once. Instead, it actively reconciles the intent declared in the resource, with the actual state of the managed entity. If the state of the entity changes (a Pod is destroyed), Kubernetes will modify or recreate the entity to match the desired state. And of course if the intended state changes, Kubernetes will actuate the new intention. Speaking precisely, a controller manages one or a few very closely related types of resources. A controller manager is single binary that embeds multiple controllers, and an operator is a set of these that manages a particular type of workload. Speaking loosely, controller and operator are often used interchangeably, though an operator always refers to code managing CRs rather than Kubernetes built-in types.
All Kubernetes resources have a metadata field that contains the name, namespace (if not cluster scoped), annotations and labels for the resource. Most resources also have a spec and a status field. The spec field holds the intended state, and the status field holds the observed state and any control data needed by the controller to do its job. Typically, controllers read the spec and write the status.
Kpt
Kpt is a GitOps based package management tool for Kubernetes. It uses configuration-as-data principle. For more details refer to Kpt book.
Porch
Package Orchestration service (Porch) enables workflows similar to those supported by the kpt CLI, but makes them available as a Kubernetes service. For more details refer to Porch user guide.
ConfigSync
Config Sync lets cluster operators and platform administrators deploy consistent configurations and policies. You can deploy these configurations and policies to individual Kubernetes clusters, multiple clusters that can span hybrid and multi-cloud environments, and multiple namespaces within clusters. This process simplifies and automates configuration and policy management at scale. Config Sync also lets development teams independently manage their namespaces within clusters, while still being subject to policy guardrails set by administrators.
Config Sync is an open-source project and the source and releases available here.
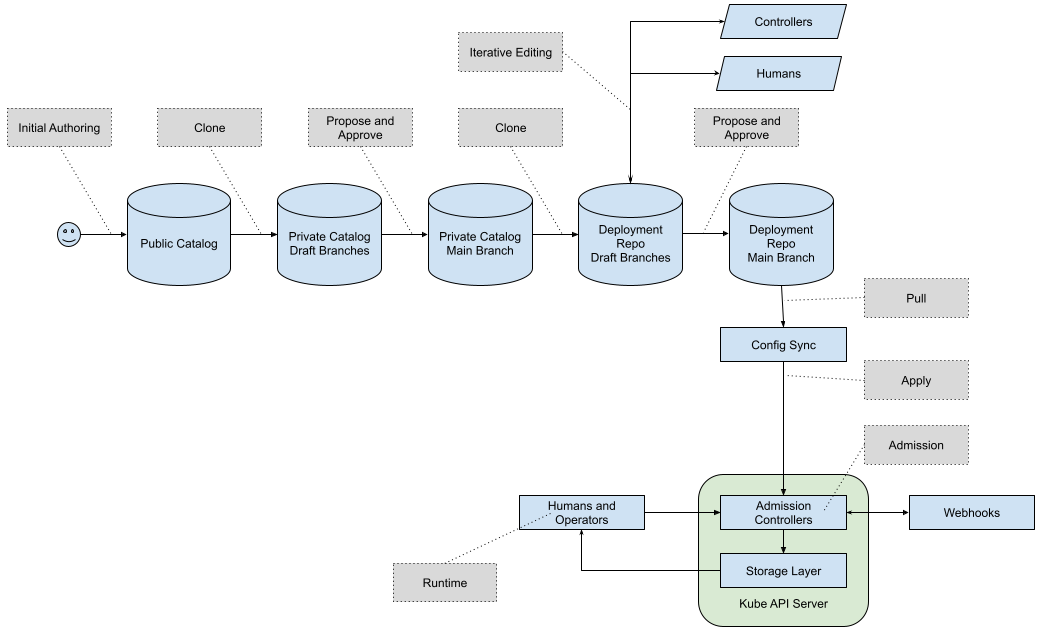
Packages
Packages or Kpt Packages are bundles of Kubernetes resource files, along with a Kptfile (also in Kubernetes Resource Model (KRM) format). They provide the basic unit of management in the Kpt toolchain. This toolchain is used to manage the configuration before it reaches the Kubernetes API server. This “shift left” model is critical to allowing safe collaborative, automated configuration creation and editing, because errors or partial configurations can be resolved prior to affecting operations.
Following the configuration-as-data principle, the package is not encapsulated. Since the contents of the package is simply KRM resources, independently designed tools and automations can operate on those resources. Instead of an encapsulated abstract interface where inputs are provided and manifests are rendered, we have an open concept we refer to as “the package is the interface”.
In order to allow multiple actors to operate on that open package safely, we mediate the process via an API layer called Porch (for “Package Orchestration”). Porch provides a Kubernetes API for manipulating packages, their contents, and how they map to repositories (which may be Git or OCI repositories).
In Porch, packages always live within a repository. A package may have many package revisions, or versions of the package, within the same repository. A draft package revision lives in a draft branch, not in the main branch. When a draft is ready to be used, it may be proposed for publication. If the proposed draft is approved it becomes a published revision, and is assigned a revision number by Porch. Published packages are tagged in the underlying repository. A given package can have many revisions, but they are all sequentially ordered as “v1”, “v2”, “v3”, etc. This version is the revision number of the configuration package, not the underlying software contained in the package. This simple sequential numbering makes it easier to do automatic discovery of configuration package updates.
There are a few different techniques we have for manipulating the content of packages. The simplest and most basic is to just edit the files. Since the “package is the interface”, it is perfectly fine to simply edit files within the package directly, and save them. The fact that the package is all KRM data makes it relatively easy to merge upstream changes with downstream changes.
The next simplest is with KRM functions, also known as kpt functions. These are small pieces of reusable code that perform a single purpose in manipulating the configuration. When executed, a KRM function typically is provided with all the resources in the package, and modifies them however it needs to, and then emits the updated list as output. A KRM function can be called imperatively, by simply executing it against the package. This can be used, for example, with the search-and-replace function to do a one-time change across many resources in a package. Or, a KRM function can be setup in the Kptfile to be called declaratively; it will be called every time Porch saves the package. This is useful for functions that want to make sure information is consistent across several resources within a package. For example, the set-namespace function can be used to ensure the namespace is set correctly across all resources in a package, even if a new resource is added later.
Functions are intended to be simple, and hermetic. This means they do not reach out to other systems to gather information. They do not have network access nor can they mount volumes. Instead, they simply take the inputs provided in the package resources, and modify or generate other resources based on those.
Sometimes in order to create a re-usable function, that function will need inputs. For simpler functions, inputs are captured via ConfigMap resources within the Kptfile directly. For more complex function inputs, a function-specific custom resource can be used. These resources though only live within the package; we do not want them actually pushed to the cluster when we deploy the package. To avoid that, we add a special annotation on the resources, config.kubernetes.io/local-config: “true”. We thus often refer to these types of resources as “local config” resources.
Stepping up the power and complexity level, the fact that Porch is a Kubernetes API service means that we can build Kubernetes controllers on top of it. This is exactly what we are doing in Nephio.
Package Ancestry
A package may have a single upstream parent, and many downstream descendants. The Kptfiles in these packages are used to maintain the relationships, capturing ancestry relationships like those shown below.
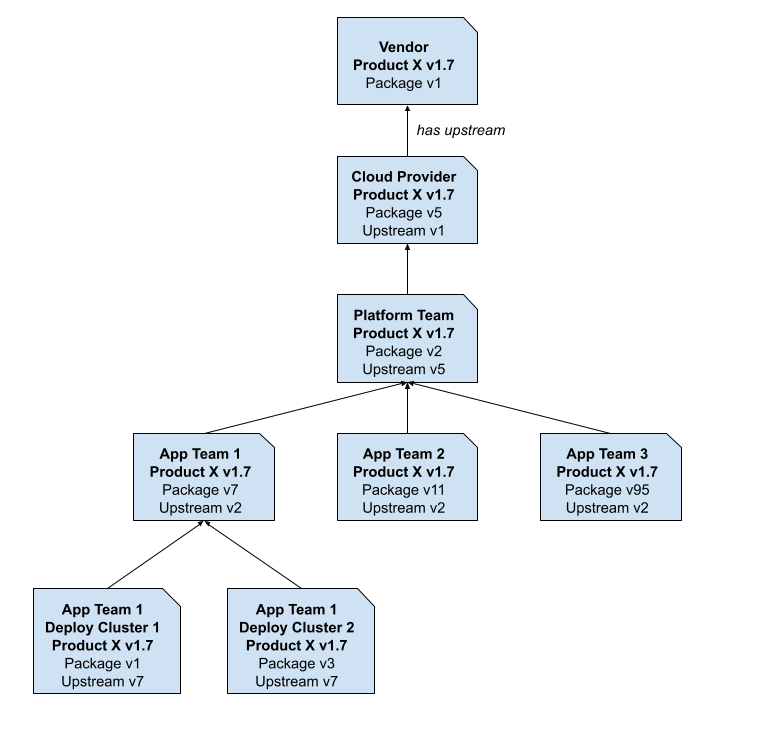
By tracking these relationships, changes at the original source can be propagated via controlled automation down the tree.
Package Configuration Journey
R1 scope
API
CRDs provided for UPF, SMF and AMF 5g core services Specialization CRDs provided for integrating with IP address and VLAN allocation backends.
Web UI
Basic web UI to view and manage Package Variants and Package variant sets.
Packages
- Kpt packages for all free5gc services
- Packages for core Nephio services
- Packages for cluster API services for cluster creation
- Packages for dependent services
Functionalities
- Create Kubernetes clusters. This functionality is based on cluster API. At this time only KIND clusters creation is supported.
- Fully automated deployment of UPF, SMF and AMF services of free5Gc . These are deployed on multiple clusters based on user’s intent expressed via CRDs.
- Inter cluster networking setup.
- Deployment of other free5gc functions. Some manual configuration such as IP addresses may be needed for these services.
- Auto-scale up of UPF, SMF and AMF services based on changes to capacity requirements expressed as user intent.
Deployment model
For the purposes of Nephio deployment, we can categorize clusters into two varieties:
- Management cluster: This is where the majority of Nephio components are installed. It is dedicated to manage the deployment and lifecycle management of network functions that will be deployed on workload clusters.
- Workload cluster: This is where the actual network function workloads are deployed and running.
The diagram below depicts deployment at the high level.
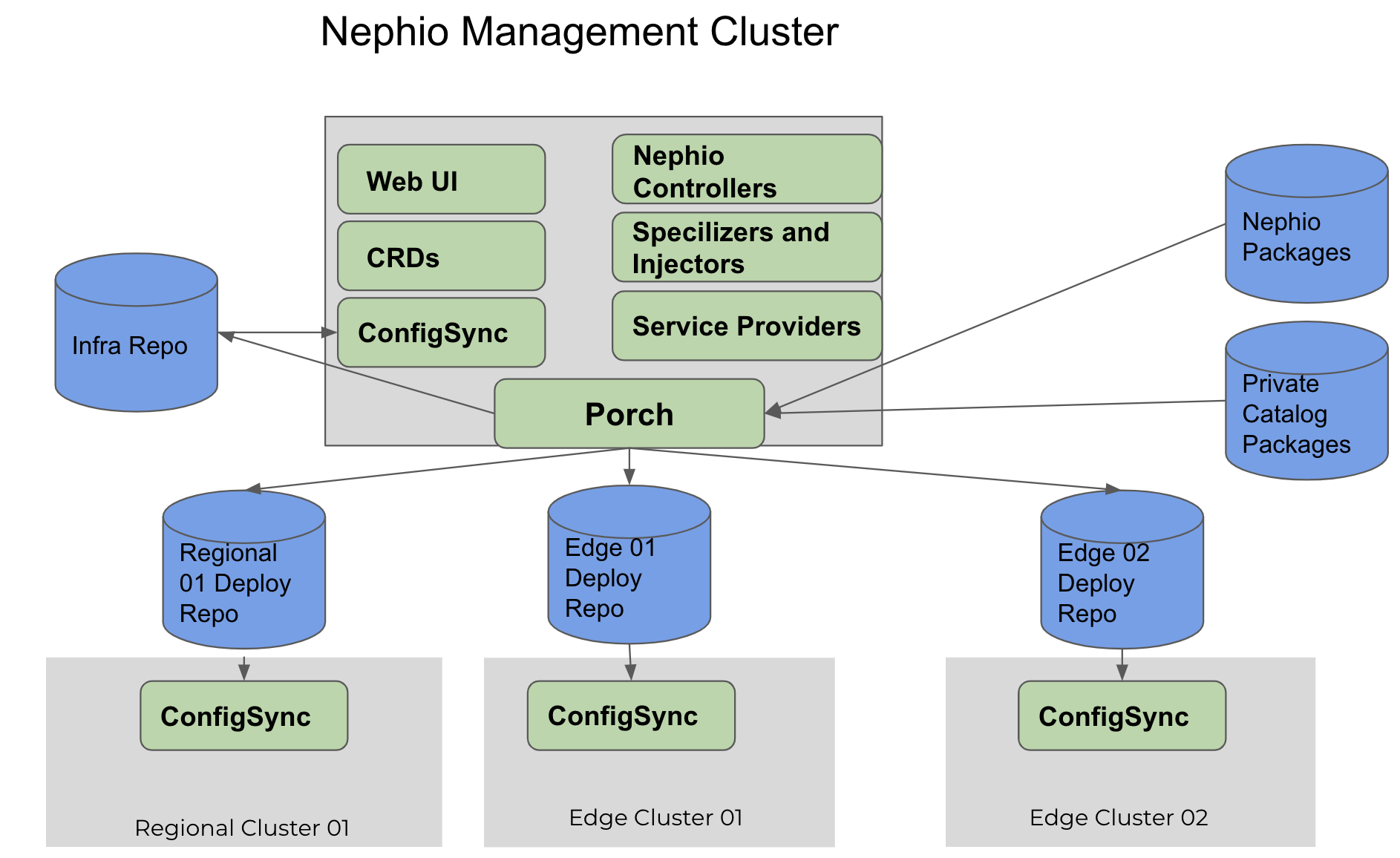
Management Cluster Components
Infrastructure Components
- Porch
- ConfigSync
Nephio Controllers
- Nephio Controller Operator
- Vlan and IPAM Controller
- Cluster API Infrastructure controller
- Status Aggregator
Specializers and Injectors (KRM Functions)
- VLAN
- IPAM
- NAD - NetworkAttachmentDefinition
- DNN - DataNetwork
UI Components
- Nephio Web UI
CRDs
- UPF
- SMF
- AMF
Workload Cluster Components
Infrastructure Components
- ConfigSync
Nephio Controllers
- Watcher agent
Workloads
- Workload operators (eg: free5gc operator)
- Workload controllers (eg: free5gc smf/upf/amf controllers)
General Workflow
NB Interfaces
- CRDs
- PVS
- Topology Controller
Management Cluster Details
- Role
- Infrastructure components (Porch, ConfigSync)
- Components
- Specializes
- Injectors
- Controllers
- Controller Manager
- IPAM and VLAN Backend
- Choreography
- Web UI
Workload Cluster Details
- Infrastructure components (ConfigSync)
- Operators
- Controllers
Instantiation of Clusters using Nephio
- Using Web UI
- Using CLI
Core free5gc Deployment
- CRDs
- Packages
- Deployment Methods (CLI, UI)
- SMF/UPF/AMF Deployment
Deployment of Other Free5gc NFs
- deployment
- Packages
- Limitations
- Manual Procedure Needed
Validation of Free5gc Deployment
- Sessions Established
- Pods Running
- Pings
- End-to-End Call
Troubleshooting and Workarounds
On the demo VM, the test-infra/e2e/provision/hacks directory contains some
workaround scripts. Also, please see the Release Notes
known issues.
Next Steps
- Learn more about the Nephio controllers
- Learn more about how packages are transformed
- Learn more about deploying helm charts in Nephio
Free5GC Testbed Deployment and E2E testing with UERANSIM
A step by step guide to deploy free5GC Core and perform E2E testing with UERANSIM
OAI Core and RAN Testbed Deployment and E2E testing
A step by step guide to deploy OAI Core and RAN network functions and perform E2E testing
Helm Integration in Nephio
User’s guides about integration Helm to Nephio